Getting Started with Hertz: Performance Testing Guide
Projects:
Background
On September 8, 2021, ByteDance officially announced the open-sourcing of CloudWeGo. CloudWeGo is a set of microservices middleware developed by ByteDance, characterized by high performance, strong scalability, and high stability. It focuses on solving the difficulties of microservices communication and governance, and meets the demands of different businesses in different scenarios. On June 21, 2022, the CloudWeGo team has officially open-sourced Hertz, ByteDance’s largest HTTP framework. Hertz has gained a lot of attention from users since its release, and has received 3K+ stars by now. Many users have tested it themselves, and we are very grateful for your attention and support. This blog aims to share the scenarios and technical issues that developers need to be aware of when conducting load testing on Hertz. These suggestions can help users better optimize Hertz based on real HTTP scenarios to better fit their business needs and achieve optimal performance. Users can also refer to the official load testing project hertz-benchmark for more details.
Characteristics of HTTP Microservices
Hertz was born out of large-scale microservices practice at ByteDance, and is naturally designed for microservices scenarios. Therefore, in the following, we will first introduce the characteristics of the HTTP microservices to facilitate developers’ deeper understanding of Hertz’s design considerations.
- HTTP Communication Model
Communication between microservices typically follows a Ping-Pong model. In addition to conventional throughput performance metrics, developers also need to consider the average latency of each HTTP request. While increasing the number of machines can quickly resolve throughput bottlenecks, reducing latency, which significantly affects user experience, is not as easy.
In the environment of microservices, a single call often requires collaboration from multiple microservices. Even if each node has low latency, the final latency on the entire chain can be amplified. Therefore, latency is a more critical metric for developers to pay attention to in microservices. Hertz has made certain optimizations for latency while ensuring throughput.
- The Use of Long and Short Connections
Since establishing a TCP connection requires a three-way handshake, the overhead of creating a new connection for each request can be very high for latency-sensitive services. Therefore, it is recommended to use persistent connections to complete requests whenever possible. In HTTP 1.1, Long connections are also the default option. However, there is no silver bullet, as maintaining connections also consumes resources, and the horizontal scalability of persistent connections is not as good as that of short connections. Therefore, in some scenarios, long connections may not be suitable. For example, in a scenario where configurations need to be pulled periodically, the connection establishment delay may not have a significant impact on configurations, and it may be more appropriate to use short connections if horizontal scalability is a concern when the configuration center is under high load.
- Packet Size
The package size of a service depends on the actual business scenario. In HTTP scenarios, data can be placed in query, path, header, body, etc., and different locations have different effects on parsing. HTTP header is an identifier protocol, and the framework does not know how many headers there are until it finds a specific identifier. Therefore, the framework needs to receive all the headers before it can complete the parsing, which is not very friendly to the framework’s memory model. Hertz has also made special optimizations for header parsing, allocating enough buffer space for headers to reduce the overhead of cross-package copying during header processing.
Meanwhile, in the internal statistics of online services at ByteDance, it was found that most packages are within 1K (but too small packages have no practical significance, such as a fixed return of “hello world”). At the same time, there is no upper limit on the size of large packages, and various package sizes are involved. Therefore, Hertz has focused on optimizing the performance (throughput and latency) of packages within the most commonly used range of 128k or less.
- Concurrency Quantity
Each instance may have multiple upstreams and will not only accept requests from a single instance. Moreover, HTTP 1 doesn’t support multiplexing, and each connection can only handle one request at a time. Therefore, the Server needs to accept multiple connections and process them simultaneously.
Different services have different connection utilization rates. For example, load testing services have high connection utilization rates, and a new request is made immediately after the completion of the previous request. Some services have low connection utilization rates, even though they are long-lived, they are only used once. The connection models used by these two services are not the same.
For the former, the goroutine per connection model should be used to reduce the overhead of context switching. For the latter, a coroutine pool should be used to reduce the scheduling overhead of too many goroutines. Hertz supports both models, and users can choose the appropriate configuration based on their business needs.
Load Testing for HTTP Scenarios
Using Scenarios That Resemble Real Usage
There are many load testing projects on GitHub and performance testing reports available online, but they may not be tailored to your specific needs.
For example, in a real-world scenario, would you create a project that only responds with hello world no matter what the client sends? Unfortunately, many load testing projects do just that.
Before conducting load testing, consider your actual usage scenarios, such as:
- Long vs Short Connections: Determine whether using long or short connections is more suitable for your scenario.
- Estimating Connection Usage: If using long connections and connection usage is high (which is the case in most scenarios), use the default configuration.
If connection usage is low, consider adding the configuration option
server.WithIdleTimeout(0)to modify the goroutine per connection model to a coroutine pool model and conduct comparative testing. - Determining Data Location and Size: As mentioned earlier, data in different locations (such as query, header, body, etc.) and of different sizes can affect the framework’s performance. If the performance of all frameworks is similar, consider using a different data transmission location.
- Determining Concurrency Quantity: Some services are lightweight on business logic but heavy on framework, resulting in high framework concurrency. Conversely, some services are heavy on business logic but light on framework, resulting in low framework concurrency.
If you just want to test the performance of the framework, you can use the common scenario: long connection, high connection usage, 1k body, 100 concurrency, and so on. The hertz-benchmark repository also uses this default load test configuration. At the same time, the hertz-benchmark repository also provides configuration options for users to modify headers, body, and concurrency, making it easy to customize the load test to fit their own needs.
Determine the Target of Load Testing
Measuring the performance of an RPC framework requires thinking from two perspectives: the Client perspective and the Server perspective. In a large-scale business architecture, the upstream Client may not necessarily use the downstream framework, and the downstream services called by developers are also likely to be different. This is even more complicated when considering the situation of Service Mesh.
Some load testing projects usually conduct load testing for Client and Server processes in a hybrid deployment, and then obtain performance data for the entire framework, which may not be consistent with the actual operation in production.
If you want to conduct load testing the Server, you should give the Client as many resources as possible and push the Server to the limit, and vice versa. If both the Client and Server are only given 4 cores for load testing, developers will not be able to determine the performance data under which perspective, let alone provide actual reference for online services.
Use Dedicated CPUs
Although online applications usually share CPUs among multiple processes, in a load testing scenario, both the Client and Server processes are extremely busy. Sharing CPUs at this time will result in a large number of context switches, which will make the data less reliable and prone to large fluctuations.
Therefore, we recommend isolating Client and Server processes on different CPUs or different dedicated machines. If you want to further avoid the impact of other processes, you can also use the nice -n -20 command to increase the scheduling priority of the load testing process.
In addition, if conditions permit, using physical machines instead of virtual machines on cloud platforms will make the test results more rigorous and reproducible.
Performance Data Reference
On the premise of meeting the above requirements, we compared the load testing result of multiple frameworks based on the latest version. The pressure test code is in the hertz-benchmark repository. With the goal of fully filling the load of Server, Hertz has the lowest P99 latency of all the frameworks tested, and the throughput is also in the first tier and under continuous optimization.
- CPU: AMD EPYC 7Y83 64-Core Processor 2.7GHz
- limits: server 4-CPUs,client 16-CPUS
- OS:Debian GNU/Linux 10 (buster)
- Go 1.19
- hertz v0.3.2,fasthttp v1.40.0, gin v1.8.1,fiber v2.38.1
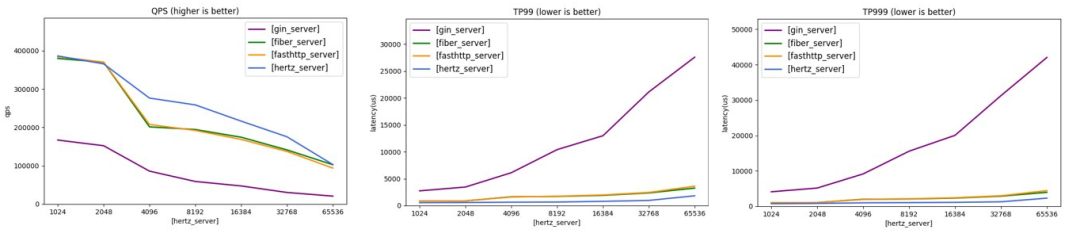
Comparison of throughput and latency of four frameworks
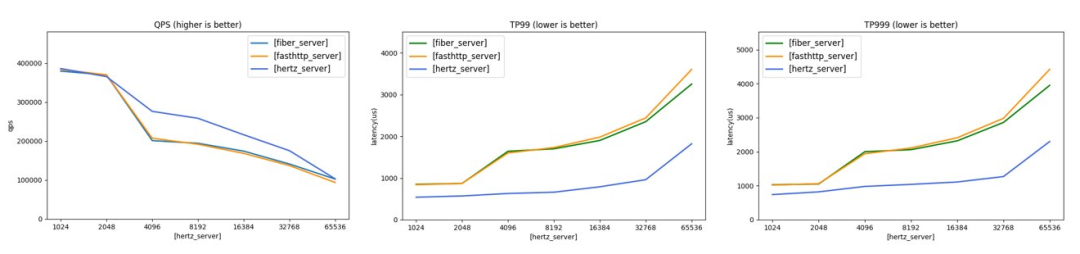
Comparison of throughput and latency of three frameworks
Conclusion
As a very large scale enterprise microservices HTTP framework, Hertz was designed to solve a variety of problems in the large-scale microservices scenario. In the process of promotion, we encountered all kinds of services and solved many kinds of problem. Based on those experience, we wrote this blog. As a developer, you are always welcome to choose the right tool for your own scenario based on the testing guide provided above. If you have any questions, feel free to raise an Issue.