优雅停机
背景
K8s 当前是社区内最主流的容器部署平台,过去社区时常会遇到在 K8s 集群中,部署的 Kitex 服务优雅停机功能不符合预期的情况。然而优雅停机与部署环境的服务注册与发现机制,以及服务自身的特性强耦合,框架和容器调度平台只是提供了「优雅停机」的能力,要真正做到优雅停机还依赖整个服务架构上的规划与配合。
出于上述目的,我们希望就这类问题从原理出发,给出一些相应的解决方案,供社区在 K8s 架构下更为合理的使用 Kitex 的优雅停机能力。 由于 K8s 架构中每一个组件都是可插拔的,不同公司尤其是实例数量上了规模的公司,对 K8s 的服务注册与发现改造程度都有所差异,所以这里我们只讨论默认的也是使用相对最广泛的 K8s 服务注册与发现模式。
K8s 服务注册
以下是一个常见的线上 Pod 的 Yaml 配置示例:
apiVersion: v1
kind: Pod
metadata:
name: xxx-service
spec:
containers:
- name: xxx-service
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
原理
K8s 在 Pod 启动后,会通过 readinessProbe 的配置,在 initialDelaySeconds 秒过后,以 periodSeconds 的周期定期检查 Pod 是否已经准备就绪提供服务,当满足 readinessProbe 定义的要求后,才会将容器 IP 真正注册到 Service 所属的健康 Endpoints 之中,从而能够被顺利服务发现。
示例中便是在 8080 端口能够被建立连接后,即认为服务属于「健康」的状态。
问题与解决方案
可访问 != 可提供服务
在上面的 YAML 示例中,我们把业务进程建立 Listener 等同于认为该进程可以提供服务。然而在复杂的业务中,这个等式不一定成立。比如一些服务可能要启动后做一系列初始化操作才能正常提供服务,如果维持上述配置,很可能出现下游滚动更新时,上游出现诸如 timeout 之类的错误,从而在现象上观察到下游其实并没有做到「优雅停机」。
针对这种情况,我们就需要定制化我们的健康检查函数:
func healthCheck() {
// 缓存预热逻辑
cache.Warming()
// 确保数据库连接池就绪
mysqlDB.Select(*).Where(...).Limit(1)
// 确保外部依赖配置中心获取到了所有必要配置
config.Ready()
// ... 其他必要依赖项检查
return
}
健康检查结果成功返回的前提,必须是确定服务已经可以正常服务请求了。
然后我们可以将该健康检查函数注册到服务中,假设是 HTTP 协议,则可以配置 readinessProbe 为:
readinessProbe:
httpGet:
scheme: HTTP
path: /health
port: 8080
如果是一些 RPC 协议(如 Kitex 默认是 Thrift 协议)或是其他更小众的协议,可以让检测程序与应用程序通过命令沟通健康状态。业务进程在启动后,只有当健康检查通过,才会去创建 /tmp/healthy 文件,以告诉 K8s 服务已经可以被访问:
readinessProbe:
exec:
command:
- cat
- /tmp/healthy
K8s 服务发现
K8s 使用 Service 来作为服务的标识名称,以下是一个常见的 Service 定义:
apiVersion: v1
kind: Service
metadata:
name: my-app
namespace: my-ns
spec:
type: ClusterIP
clusterIP: 10.1.1.101
原理
K8s 提供了通过 DNS 把一个 ServiceName 转换为一个 Cluster IP 的能力。默认情况下,Cluster IP 全局唯一且不会随着后端的 Pod 变化而变化。也就是说,Client 侧服务发现结果永远只有一个 IP 地址。
当上游通过 DNS 拿到 Cluster IP 后,直接发起对 Cluster IP 的连接,由底层操作系统通过 iptables 劫持到真正的 Pod IP 上。
问题与解决方案
无法严格负载均衡
在 iptables 机制下,Client 对 Server 的负载均衡这一步是在创建连接时候保持均衡,而 Client 看到的又只有一个固定的 Cluster IP,所以 Client 仅能做到请求在不同连接上的均衡并不能控制到在不同对端 IP 上的均衡。
而此时如果 Client 侧是长连接,那么当下游节点增加了新的 Pod 时,上游如果一直没有建立新连接,此时新节点可能会迟迟无法接受到足够多的流量,从而无法真正负载均衡。
解决方案
使用 K8s headless service:
不再使用默认的 Cluster IP,要求每个 service 服务发现返回全量真实的 Pod IP。
解决了上游对下游节点更新的感知能力的问题,实现在下游实例间真正做到流量均衡。
使用 Kitex 短连接
每一个请求独立创建一个新的短连接,可以利用上 iptables 的负载均衡能力,顺带也解决了下游销毁时上游能够平滑做到不访问到即将被销毁 Pod 的问题。
使用 Service Mesh
依赖数据面实现负载均衡,将问题下放给数据面处理。
K8s 销毁 Pod
K8s 提供了一些用以控制销毁 Pod 时行为的 Hooks:
apiVersion: v1
kind: Pod
spec:
containers:
- name: xxx-service
preStop:
exec:
command: ["sleep", "5"]
terminationGracePeriodSeconds: 30
原理
某个 Pod 将要被销毁时,K8s 会以此做以下事情:
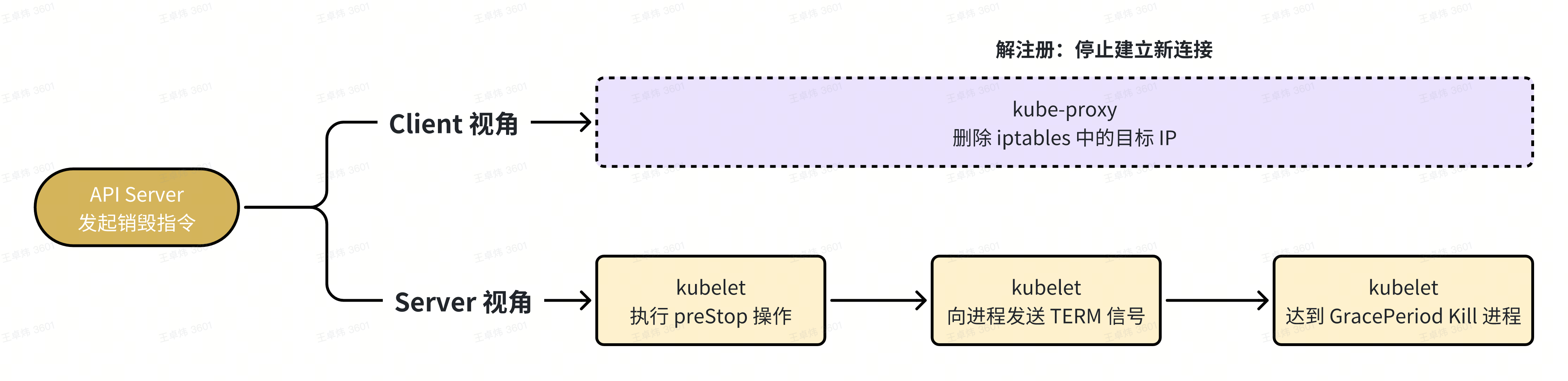
kube-proxy 删除上游 iptables 中的目标 IP
这一步虽然一般来说会是一个相对比较快的操作,不会像图里所示这么夸张,但它的执行时间依然是不受保障的,取决于集群的实例规模,变更繁忙程度等多重因素影响,所以用了虚线表示。
这一步执行完毕后,只能确保新建立的连接不再连接到老容器 IP 上,但是已经存在的连接不会受影响。
kubelet 执行 preStop 操作
由于后一步操作会立刻关闭 listener,所以这一步,我们最好是在 preStop 中,sleep N 秒的时间(这个时间取决于你集群规模),以确保 kube-proxy 能够及时通知所有上游不再对该 Pod 建立新连接。
kubelet 发送 TERM 信号
此时才会真正进入到 Kitex 能够控制的优雅关闭流程:
- 停止接受新连接:Kitex 会立刻关闭当前监听的端口,此时新进来的连接会被拒绝,已经建立的连接不影响。所以务必确保前面 preStop 中配置了足够长的等待服务发现结果更新的时间。
- 等待处理完毕旧连接:
- 非多路复用下(短连接/长连接池):
- 每隔 1s 检查所有连接是否已经都处理完毕,直到没有正在处理的连接则直接退出。
- 多路复用:
- 立即对所有连接发送一个 seqID 为 0 的 thrift 回包(控制帧),并且等待 1s(等待对端 Client 收到该控制帧 )
- Client 接收到该消息后标记当前连接为无效,不再复用它们(而当前正在发送和接收的操作并不会受到影响)。这个操作的目的是,client 已经存在的连接不再继续发送请求。
- 每隔 1s 检查所有存量连接是否已经都处理完毕,直到没有活跃连接则直接退出
- 非多路复用下(短连接/长连接池):
- 达到 Kitex 退出等待超时时间(ExitWaitTime,默认 5s)则直接退出,不管旧连接是否处理完毕。
达到 K8s terminationGracePeriodSeconds 设置的超时时间(从 Pod 进入 Termination 状态开始算起,即包含了执行 PreStop 的时间),则直接发送 KILL 信号强杀进程,不管进程是否处理完毕。
问题与解决方案
Client 无法感知即将关闭的连接
这部分问题与前面服务发现时负载均衡的问题根源上是相似的。
当下游节点开始销毁时,Client 完全依赖 kube-proxy 即时删除机器上 iptables 中的对应 Pod IP。Client 自身只管不停对这个 ClusterIP 创建连接和发送请求。
所以,如果 kube-proxy 没有及时删除已经销毁的 Pod IP ,此时就有可能创建连接出现问题。即便 kube-proxy 删除了 Pod IP 对应的规则,已经建立的连接也不会受到影响,依然会被用于发送新的请求(长连接模式时)。此时这个旧连接的下一次被使用很可能撞上对端 Pod 正在被关闭的情况,进而出现例如 connection reset 的错误。
解决方案
使用 K8s headless service:
当下线的 IP 被取消注册,上游 Kitex Client 能自动不再分配新请求给该 IP。随着后续对端 Server 关闭,会自然将上游连接也关闭。
使用 Service Mesh:
在 Mesh 模式下,控制面会接管整个服务发现机制,而数据面会接管优雅停机部分的工作,上游应用可以从服务治理细节中解放出来。
Server 无法在销毁前处理完所有请求
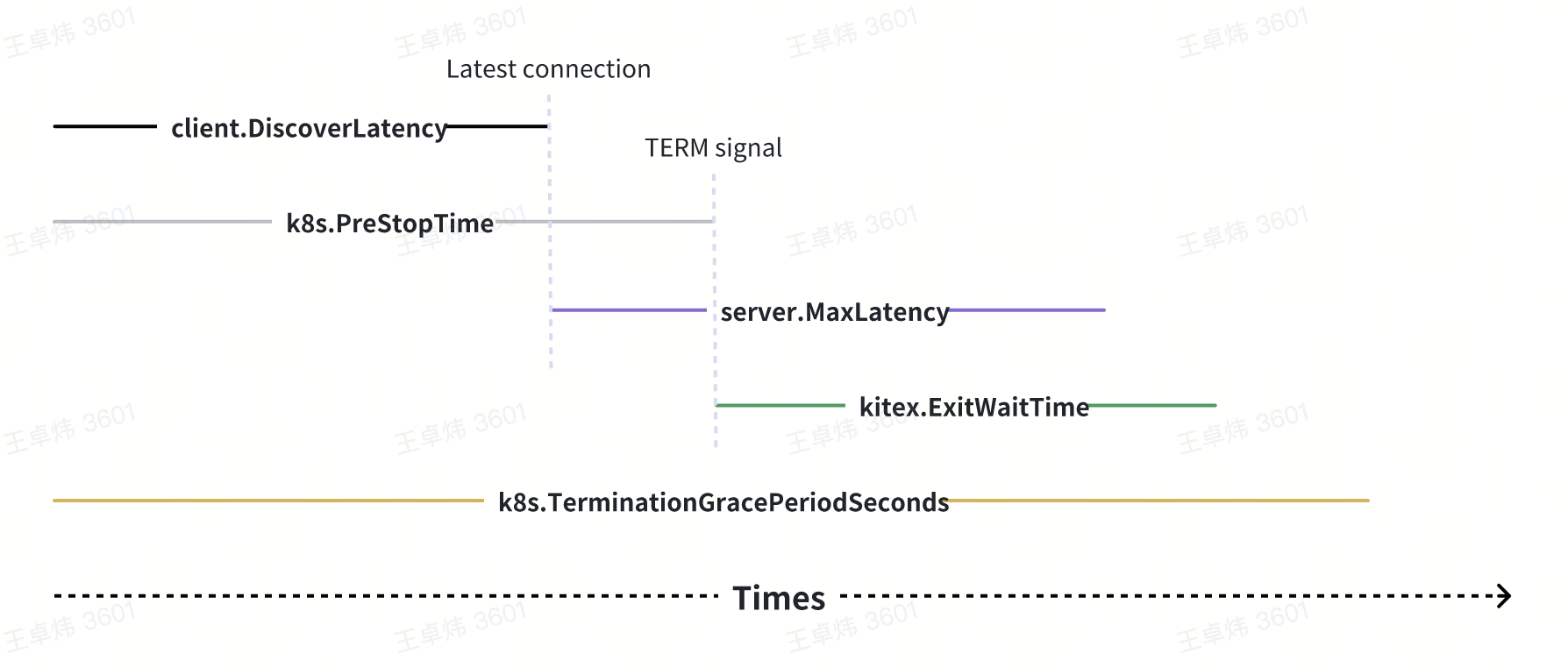
这个问题本质上取决于几个时间:
- 上游服务发现结果更新时间 (client.DiscoverLatency)
- K8s 的 preStop 等待时间(k8s.PreStopTime)
- 下游服务请求最大处理时间(server.MaxLatency)
- Kitex 框架的退出等待时间(kitex.ExitWaitTime)
- K8s 的强杀等待时间(k8s.TerminationGracePeriodSeconds)
这几个时间必须严格遵循以下时序图表示的大小关系,否则便可能出现无法优雅关闭的情况:
总结
通过以上繁杂的流程描述,可能就会发现,K8s 与 Kitex 框架都仅仅只是提供了一些参数,来让用户能够实现优雅停机,而并非保证默认的优雅停机相关配置对所有类型的服务在所有的部署环境下,都能够自动实现优雅停机的能力。事实上也不可能做到如此。
此外,虽然严格来说针对每一个具体的服务,做到接近 100% 的优雅停机是可行的,但从整体全局的服务治理而言,很少能够有足够的人力去针对每一个服务 case by case 配置相应的参数。所以在真实情况中,我们建议在了解整个系统每一个环节的原理基础上,结合业务自身总体的特点,配置一个相对宽泛安全的优雅停机默认参数即可。对于极端重要且延迟情况比较特殊的服务,再去考虑单独配置特定的参数。
最后,上游也不应当完全假设下游一定能够做到 100% 的优雅停机,也应当做一些诸如连接失败换节点重试之类的能力,以屏蔽下游小范围的节点抖动,实现更高的 SLA。