编排的设计理念
大模型应用编排框架的主流语言是 python,这门语言以其灵活性著称,灵活性给 sdk 的开发带来便利,但同时也给 sdk 的使用者带来了心智负担。
基于 golang 的 eino 则是 静态类型 ,在 Compile 时做类型检查,避免了 python 等动态语言的运行时类型问题。
以上下游 类型对齐 为基本准则
eino 的最基础编排方式为 graph,以及简化的封装 chain。不论是哪种编排方式,其本质都是 逻辑节点 + 上下游关系 。在编排的产物运行时,都是从一个逻辑节点运行,然后下一步运行和这个节点相连的下一个节点。
这之间蕴含了一个基本假设:前一个运行节点的输出值,可以作为下一个节点的输入值。
在 golang 中,要实现这个假设,有两个基本方案:
- 把不同节点的输入输出都变成一种更泛化的类型,例如
any、map[string]any等。- 采用泛化成 any 的方案,但对应的代价是: 开发者在写代码时,需要显式转换成具体类型才能使用。这会极大增加开发者的心智负担,因此最终放弃此方案。
- langchain 的方案可以看做是全程传递
map[string]any,各个逻辑节点根据自己的需要,用对应的 key 去取对应的 value。在 langchaingo 的实现中,即是按照这种方式实现,但同样,golang 中的 any 要被使用依然要使用类型断言才可使用。这种方案在开发者使用时依然有很大的心智负担。
- 每一个节点的输入输出类型保持开发者的预期,在 Compile 阶段保证上下游的类型是一致的。
方案 2 即是 eino 最终选定的方案。这种方案是编排时最容易被理解的,整个过程就像是 搭积木 一样,每一个积木突出的部分和凹陷的部分有各自的规格,仅有规格匹配了才能成为上下游关系。
就如下图:
对于一个编排而言,只有下游能识别和处理上游的输出,这个编排才能正常运行。 这个基本假设在 eino 中被清晰地表达了出来,让开发者在用 eino 做编排时,能够有十足的信心清楚编排的逻辑是如何运行和流转的,而不是从一系列的 any 中去猜测传过来的值是否正确。
graph 中的类型对齐
edge
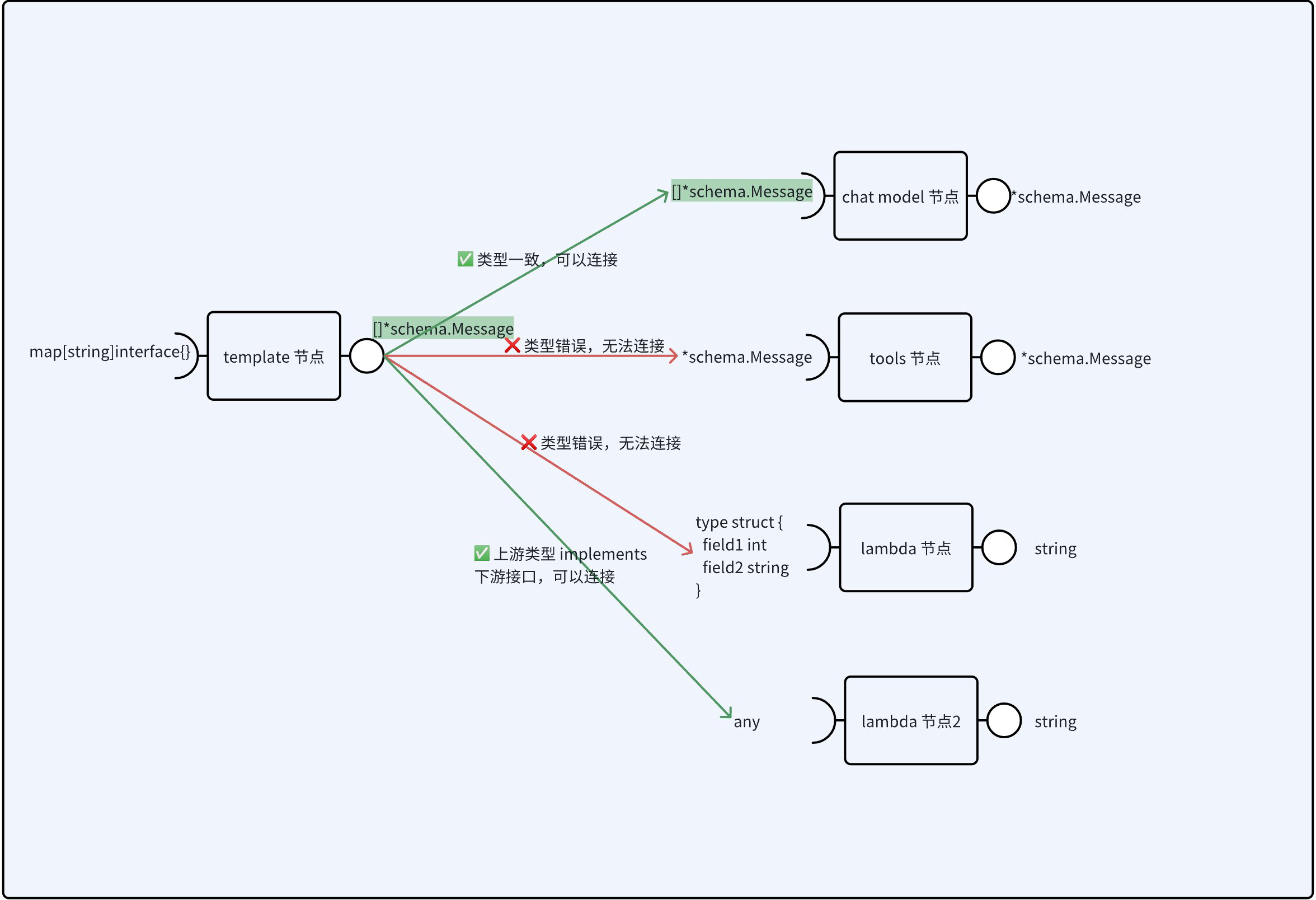
在 graph 中,一个节点的输出将顺着 边(edge) 流向下一节点,因此,用边连接的节点间必须要类型对齐。
如下图:
这是一个模拟 ① 直接和大模型对话 ② 使用 RAG 模式 的场景,最后结果可用于对比两种模式的效果
图中绿色的部分,就是普通的 Edge 连接,其要求上游的输出必须能 assign 给下游,可以接收的类型有:
① 上下游类型相同: 例如上游输出 *schema.Message 下游输入也是 *schema.Message
② 下游接收接口,上游实现了该接口: 例如上游结构体实现了 Format() 接口,下游接收的是一个 interface{ Format() }。特殊情况是下游是 any(空接口),上游一定实现了 any,因此一定可以连接。
③ 上游是 interface,下游是具体类型: 当下游具体类型 implements 上游的 interface 类型时,有可能可以,有可能不行,在 compile 时无法确定,只有在运行时,等上游的具体类型确定了,才能最终确定。时,详细描述可见: Eino: 编排的设计理念
图中黄色的部分,则是 eino 提供的另一个类型转换的机制,即: 若下游接收的类型是 map[string]any,但是上游输出的类型并不是 map[string]any,可以使用 graph.AddXXXNode(node_key, xxx, compose.WithOutputKey("outkey") 的方式将上游输出的类型转化为 map[string]any,其中 map 的 key 是 option 中指定的 OutputKey。 一般在多条边汇聚到某一个节点时,这种机制使用起来较为方便。
同理,若上游是 map[string]any ,但是下游输入的类型并不是 map[string]any,则可以使用 graph.AddXXXNode(node_key, xxx, compose.WithInputKey("inkey") 来获取上游输出的其中一个 key 的 value,作为下游的输入。
branch
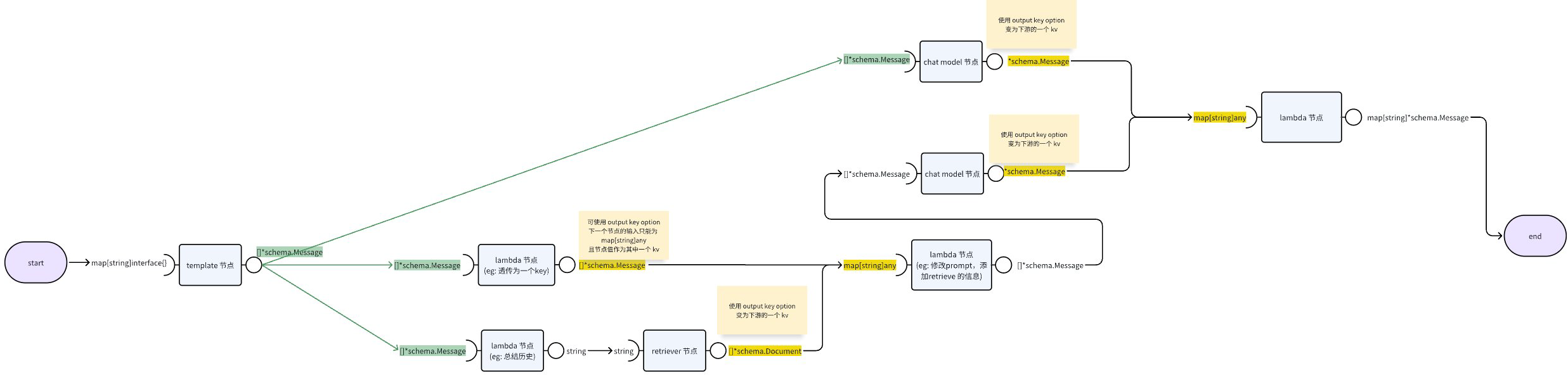
如果一个节点后面连接了多个 edge,则每条 edge 的下游节点都会运行一次。branch 则是另一种机制: 一个 branch 后接了 n 个节点,但仅会运行 condition 返回的那个 node key 对应的节点。同一个 branch 后的节点,必须要类型对齐。
如下图:
这是一个模拟 react agent 的运行逻辑

可以看到,一个 branch 本身拥有一个 condition, 这个 function 的输入必须和上游类型对齐。同时,一个 branch 后所接的各个节点,也必须和 condition 一样,要能接收上游的输出。
chain 中的类型对齐
chain
从抽象角度看,chain 就是一个 链条,如下所示:
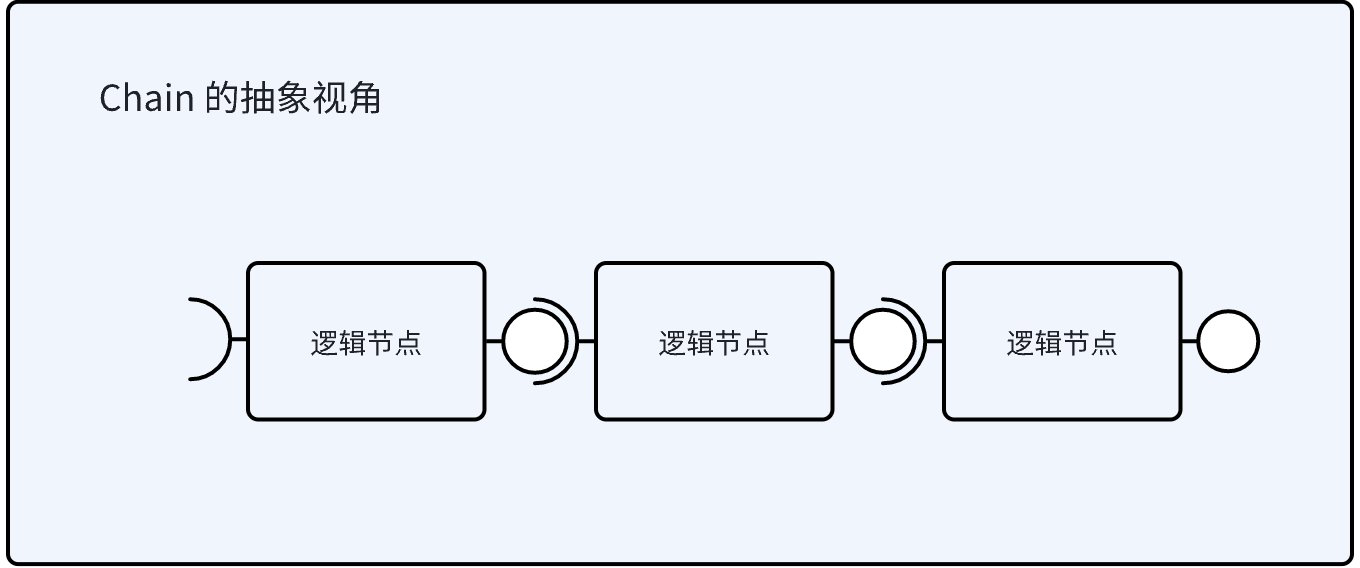
逻辑节点的类型可以分为 3 类:
- 可编排组件 (例如 chat model、 chat template、 retriever、 lambda、graph 等等)
- branch 节点
- parallel 节点
可以看到,在 chain 的视角下,不论是简单的节点(eg: chat model) 还是复杂的节点 (eg: graph、branch、parallel),都是一样的,在运行过程中,一步的执行就是一个节点的运行。
也因此,chain 的上下游节点间,类型必须是对齐的,如下:
func TestChain() {
chain := compose.NewChain[map[string]interface,string]()
nodeTemplate := &fakeChatTemplate{} // input: map[string]any, output: []*schema.Message
nodeHistoryLambda := &fakeLambda{} // input: []*schema.Message, output: []*schema.Message
nodeChatModel := &fakeChatModel{} // input: []*schema.Message, output: *schema.Message
nodeConvertResLambda := &fakeLambda{} // input: *schema.Message, output: string
chain.
AppendChatTemplate(nodeTemplate).
AppendLambda(nodeHistoryLambda).
AppendChatModel(nodeChatModel).
AppendLambda(nodeConvertResLambda)
}
上面的逻辑用图来表示如下:

若上下游的类型没有对齐,chain 会在 chain.Compile() 时返回错误。而 graph 会在 graph.AddXXXNode() 时就报错。
parallel
parallel 在 chain 中是一类特殊的节点,从 chain 的角度看 parallel 和其他的节点没啥区别。在 parallel 内部,其基本拓扑结构如下:
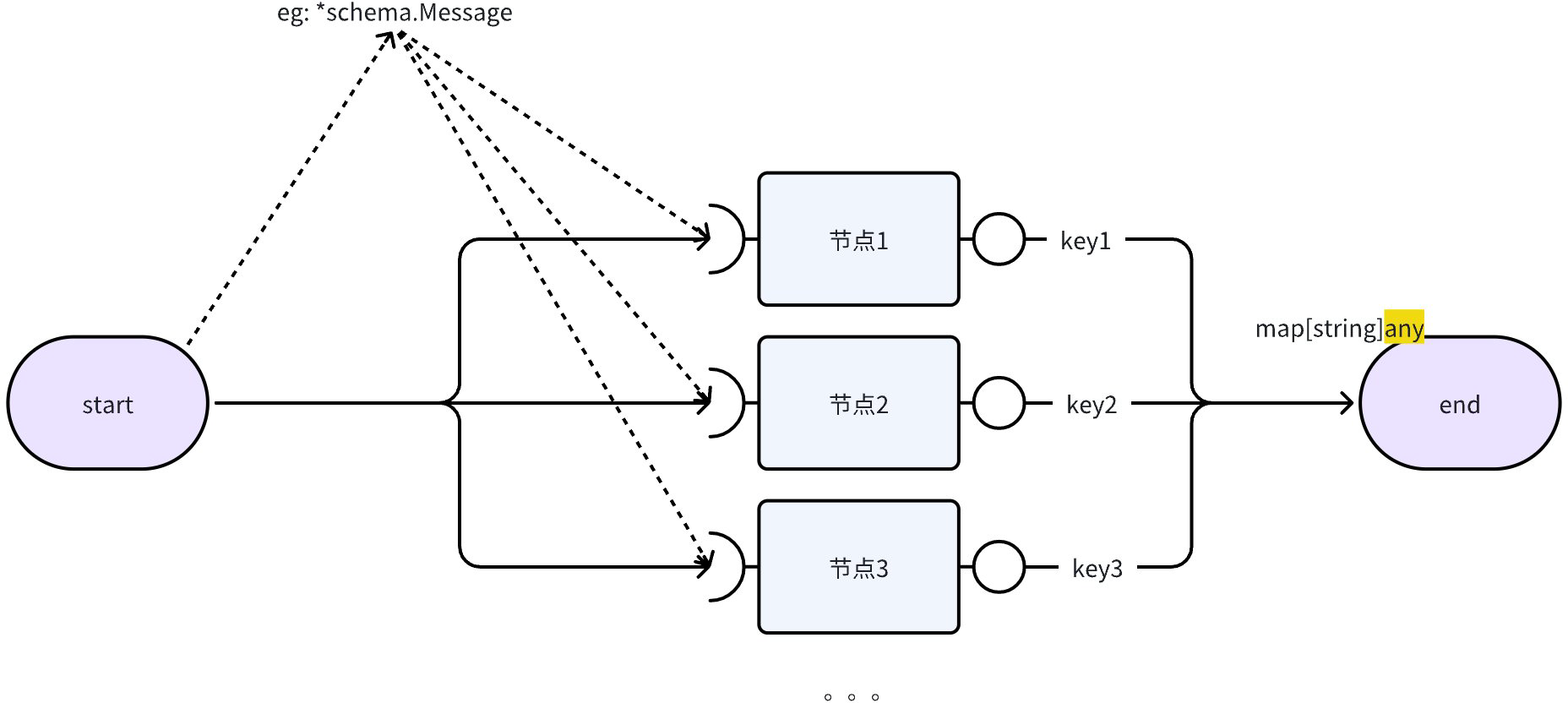
graph 中的多 edge 形成的结构其中一种就是这个,这里的基本假设是: 一个 parallel 的每一条边上有且仅有一个节点。当然,这一个节点也可以是 graph。但注意,目前框架没有直接提供在 parallel 中嵌套 branch 或 parallel 的能力。
在 parallel 中的每个节点,由于其上游节点是同一个,因此他们都要和上游节点的输出类型对齐,比如图中上游节点输出了 *schema.Message ,则每个节点都要能接收这个类型。接收的方式和 graph 中的一致,通常可以用 相同类型 、接口定义 、any、input key option 的方式。
parallel 节点的输出一定是一个 map[string]any,其中的 key 则是在 parallel.AddXXX(output_key, xxx, opts...) 时指定的 output_key,value 是节点内部的实际输出。
一个 parallel 的构建例子如下:
func TestParallel() {
chain := compose.NewChain[map[string]any, map[string]*schema.Message]()
parallel := compose.NewParallel()
model01 := &fakeChatModel{} // input: []*schema.Message, output: *schema.Message
model02 := &fakeChatModel{} // input: []*schema.Message, output: *schema.Message
model03 := &fakeChatModel{} // input: []*schema.Message, output: *schema.Message
parallel.
AddChatModel("outkey_01", model01).
AddChatModel("outkey_02", model02).
AddChatModel("outkey_03", model03)
lambdaNode := &fakeLambdaNode{} // input: map[string]any, output: map[string]*schema.Message
chain.
AppendParallel(parallel).
AppendLambda(lambdaNode)
}
一个 parallel 在 chain 中的视角如下:
图中是模拟同一个提问,由不同的大模型去回答,结果可用于对比效果
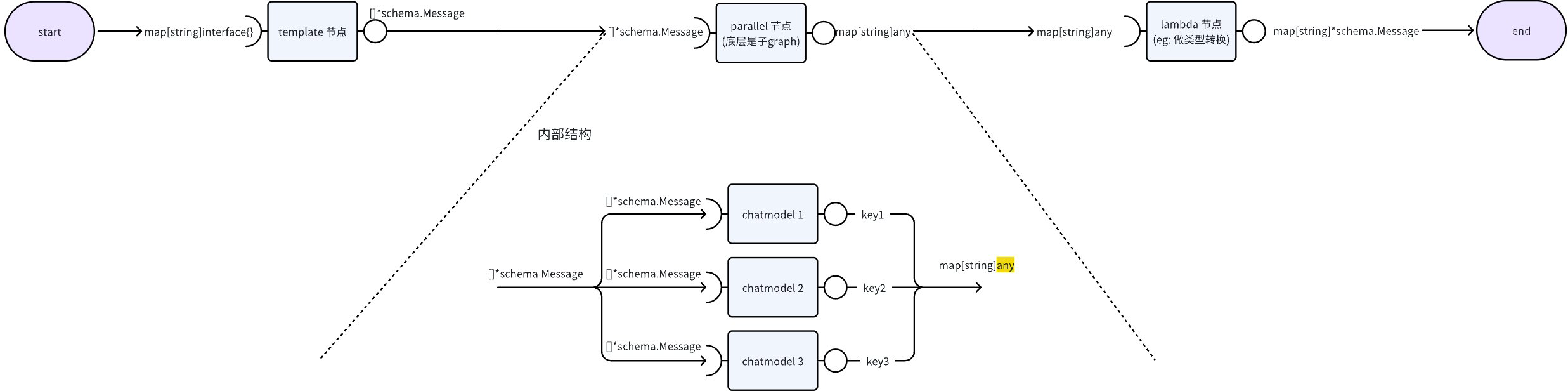
需要注意的是,这个结构只是逻辑上的视角,由于 chain 本身也是用 graph 实现的,parallel 在底层 graph 中会平铺到图中。
branch
chain 的 branch 和 graph 中的 branch 类似,branch 中的所有节点都要和上游节点的类型对齐,此处不再赘述。chain branch 的特殊之处是,branch 的所有可能的分支节点,都会连到 chain 中的同一个节点,或者都会连到 END。
Workflow 中的类型对齐
Workflow 的类型对齐的维度,由整体的 Input & Output 改成了字段级别。具体可分为:
- 上游输出的整体,类型对齐到下游的某个具体字段。
- 上游输出的某个具体字段,类型对齐到下游的整体。
- 上游输出的某个具体字段,类型对齐到下游输入的某个具体字段。
原理和规则与整体的类型对齐相同。
StateHandler 的类型对齐
StatePreHandler: 输入类型需要对齐对应节点的非流式输入类型。
// input 类型为 []*schema.Message,对齐 ChatModel 的非流式输入类型
preHandler := func(ctx context.Context, input []*schema.Message, state *state) ([]*schema.Message, error) {
// your handler logic
}
AddChatModelNode("xxx", model, WithStatePreHandler(preHandler))
StatePostHandler: 输入类型需要对齐对应节点的非流式输出类型。
// input 类型为 *schema.Message,对齐 ChatModel 的非流式输出类型
postHandler := func(ctx context.Context, input *schema.Message, state *state) (*schema.Message, error) {
// your handler logic
}
AddChatModelNode("xxx", model, WithStatePostHandler(postHandler))
StreamStatePreHandler: 输入类型需要对齐对应节点的流式输入类型。
// input 类型为 *schema.StreamReader[[]*schema.Message],对齐 ChatModel 的流式输入类型
preHandler := func(ctx context.Context, input *schema.StreamReader[[]*schema.Message], state *state) (*schema.StreamReader[[]*schema.Message], error) {
// your handler logic
}
AddChatModelNode("xxx", model, WithStreamStatePreHandler(preHandler))
StreamStatePostHandler: 输入类型需要对齐对应节点的流式输出类型。
// input 类型为 *schema.StreamReader[*schema.Message],对齐 ChatModel 的流式输出类型
postHandler := func(ctx context.Context, input *schema.StreamReader[*schema.Message], state *state) (*schema.StreamReader[*schema.Message], error) {
// your handler logic
}
AddChatModelNode("xxx", model, WithStreamStatePostHandler(postHandler))
invoke 和 stream 下的类型对齐方式
在 Eino 中,编排的结果是 graph 或 chain,若要运行,则需要使用 Compile() 来生成一个 Runnable 接口。
Runnable 的一个重要作用就是提供了 「Invoke」、「Stream」、「Collect」、「Transform」 四种调用方式。
上述几种调用方式的介绍以及详细的 Runnable 介绍可以查看: Eino 流式编程要点
假设我们有一个 Graph[[]*schema.Message, []*schema.Message],里面有一个 ChatModel 节点,一个 Lambda 节点,Compile 之后是一个 Runnable[[]*schema.Message, []*schema.Message]。
package main
import (
"context"
"io"
"testing"
"github.com/cloudwego/eino/compose"
"github.com/cloudwego/eino/schema"
"github.com/stretchr/testify/assert"
)
func TestTypeMatch(t *testing.T) {
ctx := context.Background()
g1 := compose.NewGraph[[]*schema.Message, string]()
_ = g1.AddChatModelNode("model", &mockChatModel{})
_ = g1.AddLambdaNode("lambda", compose.InvokableLambda(func(_ context.Context, msg *schema.Message) (string, error) {
return msg.Content, nil
}))
_ = g1.AddEdge(compose.START, "model")
_ = g1.AddEdge("model", "lambda")
_ = g1.AddEdge("lambda", compose.END)
runner, err := g1.Compile(ctx)
assert.NoError(t, err)
c, err := runner.Invoke(ctx, []*schema.Message{
schema.UserMessage("what's the weather in beijing?"),
})
assert.NoError(t, err)
assert.Equal(t, "the weather is good", c)
s, err := runner.Stream(ctx, []*schema.Message{
schema.UserMessage("what's the weather in beijing?"),
})
assert.NoError(t, err)
var fullStr string
for {
chunk, err := s.Recv()
if err != nil {
if err == io.EOF {
break
}
panic(err)
}
fullStr += chunk
}
assert.Equal(t, c, fullStr)
}
当我们以 Stream 方式调用上面编译好的 Runnable 时,model 节点会输出 *schema.StreamReader[*Message],但是 lambda 节点是 InvokableLambda,只接收非流式的 *schema.Message 作为输入。这也符合类型对齐规则,因为 Eino 框架会自动把流式的 Message 拼接成完整的 Message。
在 stream 模式下,拼接帧 是一个非常常见的操作,拼接时,会先把 *StreamReader[T] 中的所有元素取出来转成 []T,再尝试把 []T 拼接成一个完整的 T。框架内已经内置支持了如下类型的拼接:
*schema.Message: 详情见schema.``ConcatMessages``()string: 实现逻辑等同于+=[]*schema.Message: 详情见compose.concatMessageArray()Map: 把相同 key 的 val 进行合并,合并逻辑同上,若存在无法合并的类型,则失败 (ps: 不是覆盖)- 其他 slice:只有当 slice 中只有一个元素是非零值时,才能合并。
对其他场景,或者当用户想用定制逻辑覆盖掉上面的默认行为时,开发者可自行实现 concat 方法,并使用 compose.RegisterStreamChunkConcatFunc() 注册到全局的拼接函数中。
示例如下:
// 假设我们自己的结构体如下
type tStreamConcatItemForTest struct {
s string
}
// 实现一个拼接的方法
func concatTStreamForTest(items []*tStreamConcatItemForTest) (*tStreamConcatItemForTest, error) {
var s string
for _, item := range items {
s += item.s
}
return &tStreamConcatItemForTest{s: s}, nil
}
func Init() {
// 注册到全局的拼接方法中
compose.RegisterStreamChunkConcatFunc(concatTStreamForTest)
}
类型对齐在运行时检查的场景
eino 的 Graph 类型对齐检查,会在 err = graph.AddEdge("node1", "node2") 时检查两个节点类型是否匹配,也就能在 构建 graph 的过程,或 Compile 的过程 发现类型不匹配的错误,这适用于 Eino: 编排的设计理念 中所列举的 ① ② ③ 条规则。
当上游节点的输出为 interface 时,若下游节点类型实现了该 interface,则上游有可能可以转成下游类型 (类型断言),但只能在 运行过程 才能清楚能否转换成功,该场景的类型检查移到了运行过程中。
其结构可见下图:
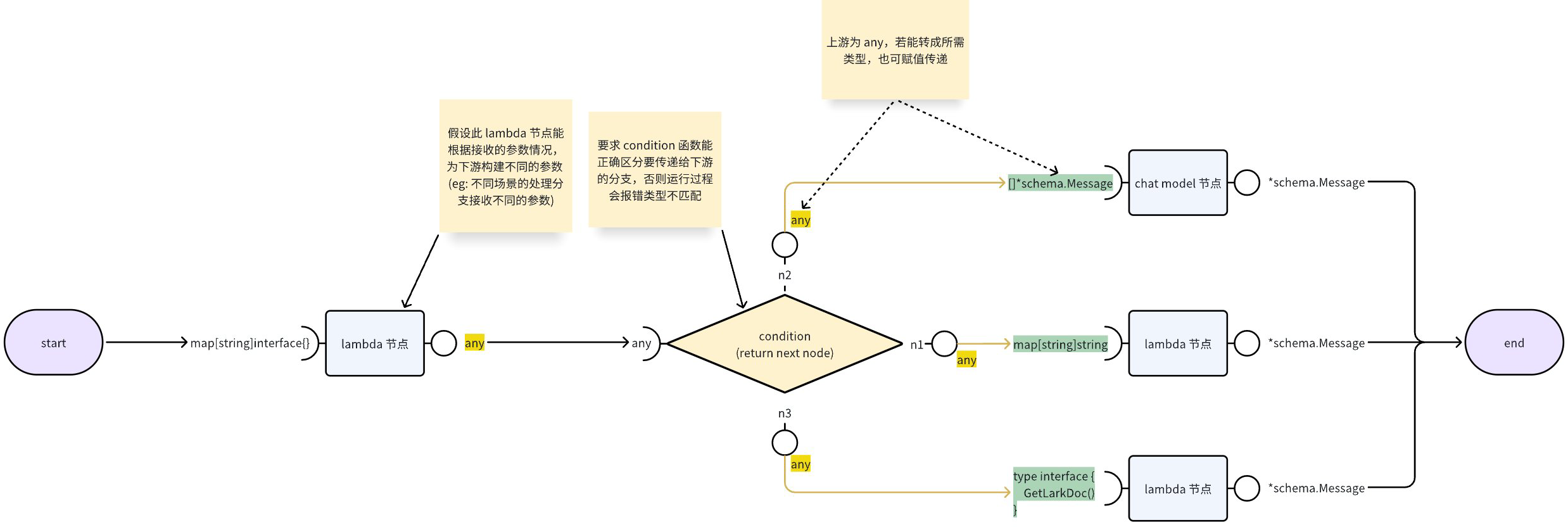
这种场景适用于开发者能自行处理好上下游类型对齐的情况,可根据不同类型选择下游执行节点。
带有明确倾向性的设计选择
外部变量只读原则
Eino 的 Graph 中的数据在 Node、Branch、Handler 间流转时,一律是变量赋值,不是 Copy。当 Input 是引用类型,如 Struct 指针、map、slice 时,在 Node、Branch、Handler 内部对 Input 的修改,会对外部有副作用,可能导致并发问题。因此,Eino 遵循外部变量只读原则:Node、Branch、Handler 内部不对 Input 做修改,如需修改,先自行 Copy。
这个原则对 StreamReader 中的 Chunk 同样生效。
扇入与合并
扇入:多个上游的数据汇入到下游,一起作为下游的输入。需要明确定义多个上游的输出,如何**合并(Merge)**起来。
默认情况下,首先要求多个上游输出的实际类型必须相同且为 Map,且相互间 key 不可重复。其次:
- 在非流式场景下,合并后成为一个 Map,包含所有上游的所有键值对。
- 在流式场景下,将类型相同的多个上游 StreamReader 合并为一个 StreamReader。实际 Recv 时效果为从多个上游 StreamReader 中公平读取。
在 AddNode 时,可以通过添加 WithOutputKey 这个 Option 来把节点的输出转成 Map:
// 这个节点的输出,会从 string 改成 map[string]any,
// 且 map 中只有一个元素,key 是 your_output_key,value 是实际的的节点输出的 string
graph.AddLambdaNode("your_node_key", compose.InvokableLambda(func(ctx context.Context, input []*schema.Message) (str string, err error) {
// your logic
return
}), compose.WithOutputKey("your_output_key"))
也可以通过注册 Merge 方法来实现任意类型的 merge:
// eino/compose/values_merge.go
func RegisterValuesMergeFunc[T any](fn func([]T) (T, error))
Workflow 可以做到多个上游的多个输出字段映射到下游节点的不同字段。这并不属于合并场景,而是点对点的字段映射。事实上,eino workflow 目前不支持“多个上游字段同时映射到相同的下游字段”。
流式处理
Eino 认为,组件应当只需要实现业务场景中真实的流式范式,比如 ChatModel 不需要实现 Collect。因此,在编排场景中,Eino 自动帮助所有的节点补全缺失的流式范式。
以 Invoke 方式运行 Graph,内部各节点均以 Invoke 范式运行,以 Stream, Collect 或 Transform 方式运行 Graph,内部各节点均以 Transform 范式运行。
自动拼接(Concatenate):Stream chunk 拼接为完整内容的场景,优先使用用户注册的自定义拼接函数,其次执行框架提供的默认行为,包括 Message, Message 数组,String,Map 和 Struct 及 Struct 指针。
自动流化(Box):需要将非流式的 T 变成 StreamReader[T] 的场景,框架自动执行。
自动合并(Merge):见上文“扇入与合并”环节。
自动复制(Copy):在需要做流的复制的场景自动进行流的复制,包括一个流扇出到多个下游节点,一个流进入一个或多个 callback handler。
最后,Eino 要求所有编排元素能够感知和处理流。包括 branch,state handler,callback handler,passthrough,lambda 等。
关于 Eino 对流的处理能力,详见 Eino 流式编程要点。
全局状态
State:在 NewGraph 时通过 compose.WithGenLocalState 传入 State 的创建方法。这个请求维度的全局状态在一次请求的各环节可读写使用。
Eino 推荐用 StatePreHandler 和 StatePostHandler,功能定位是:
- StatePreHandler:在每个节点执行前读写 State,以及按需替换节点的 Input。输入需对齐节点的非流式输入类型。
- StatePostHandler:在每个节点执行后读写 State,以及按需替换节点的 Output。输入需对齐节点的非流式输出类型。
针对流式场景,使用对应的 StreamStatePreHandler 和 StreamStatePostHandler,输入需分别对齐节点的流式输入和流式输出类型。
这些 state handlers 位于节点外部,通过对 Input 或 Output 的修改影响节点,从而保证了节点的“状态无关”特性。
如果需要在节点内部读写 State,Eino 提供了 ProcessState[S any](ctx context.Context**, handler func(context.Context, **S) error) error 函数。
Eino 框架会在所有读写 State 的位置加锁。
回调注入
Eino 编排框架认为,进入编排的组件,可能内部埋入了 Callback 切面,也可以没有。这个信息由组件是否实现了 Checker 接口,以及接口中 IsCallbacksEnabled 方法的返回值来判断。
- 当
IsCallbacksEnabled返回 true 时,Eino 编排框架使用组件实现内部的 Callback 切面。 - 否则,自动在组件实现外部包上 Callback 切面,(只能)上报 input 和 output。
无论哪种,都会自动推断出 RunInfo。
同时,对 Graph 整体,也一定会注入 Callback 切面,RunInfo 为 Graph 自身。
关于 Eino 的 Callback 能力完整说明,见 Eino: Callback 用户手册。
Option 分配
Eino 支持各种维度的 Call Option 分配方式:
- 默认全局,即分配到所有节点,包括嵌套的内部图。
- 可添加某个组件类型的 Option,这时默认分配到该类型的所有节点,比如 AddChatModelOption。定义了独有 Option 类型的 Lambda,也可以这样把 Option 指定到自身。
- 可指定任意个具体的节点,使用
DesignateNode(key ...string). - 可指定任意深度的嵌套图,或者其中的任意个具体的节点,使用
DesignateNodeWithPath(path ...*NodePath).
关于 Eino 的 Call Option 能力完整说明,见 Eino: CallOption 能力与规范。
图嵌套
图编排产物 Runnable 与 Lambda 的接口形式非常相似。因此编译好的图可以简单的封装为 Lambda,并以 Lambda 节点的形式嵌套进其他图中。
另一种方式,在编译前,Graph,Chain,Workflow 等都可以直接通过 AddGraph 的方式嵌套进其他图中。两个方式的差异是:
- Lambda 的方式,在 trace 上会多一级 Lambda 节点。其他 Callback handler 视角看也会多一层。
- Lambda 的方式,需要通过 Lambda 的 Option 来承接 CallOption,无法通过 DesignateNodeWithPath。
- Lambda 的方式,内部图需事先编译。直接 AddGraph,则内部图随上级图一起编译。
内部机制
执行时序
以一个添加了 StatePreHandler、StatePostHandler、InputKey、OutputKey,且内部没有实现 Callback 切面的 InvokableLambda(输入为 string,输出为 int)为例,在图中的流式执行完整时序如下:
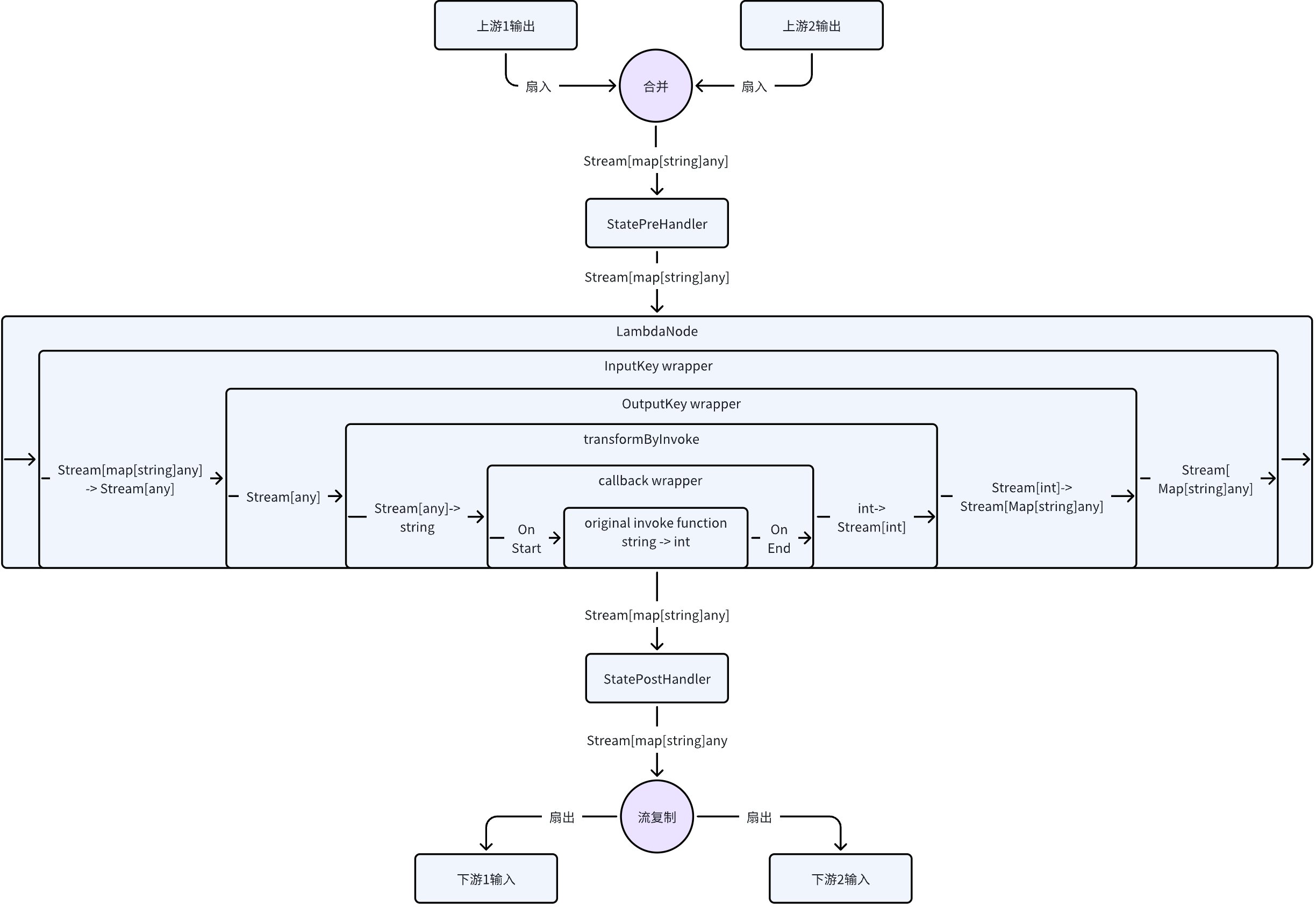
在 workflow 的场景中,字段映射发生在两个位置:
- 在节点执行后的 StatePostHandler 以及“流复制”步骤后,每个下游需要的字段会分别抽取出来。
- 在节点执行前的“合并”步骤之后、StatePreHandler 之前,会将抽取出来的上游字段值转换为当前节点的输入。
运行引擎
NodeTriggerMode == AnyPredecessor 时,图以 pregel 引擎执行,对应的拓扑结构是有向有环图。特点是:
- 当前执行中的一个或多个节点,所有的后序节点,作为一个 SuperStep,整体一起执行。这时,这些新的节点,会成为“当前”节点。
- 支持 Branch,支持图中有环,但是可能需要人为添加 passthrough 节点,来确保 SuperStep 中的节点符合预期,如下图:
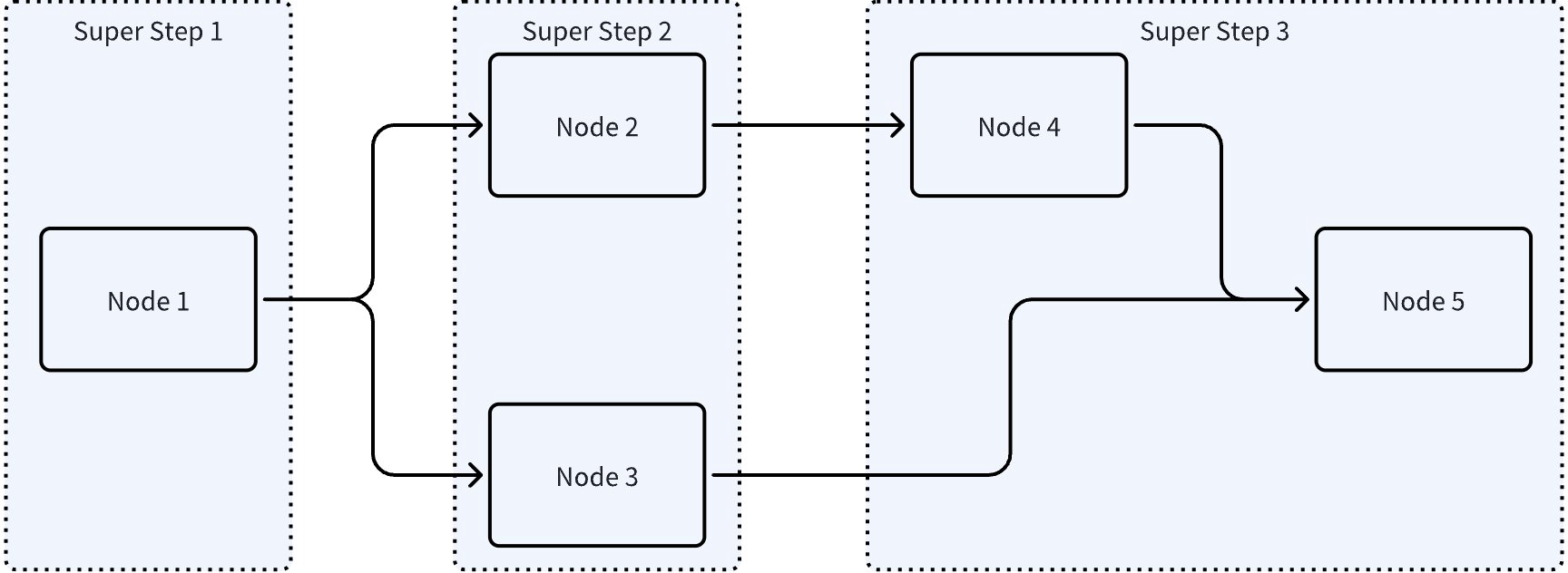
上图中 Node 4 和 Node 5 按规则被放在一起执行,大概率不符合预期。需要改成:
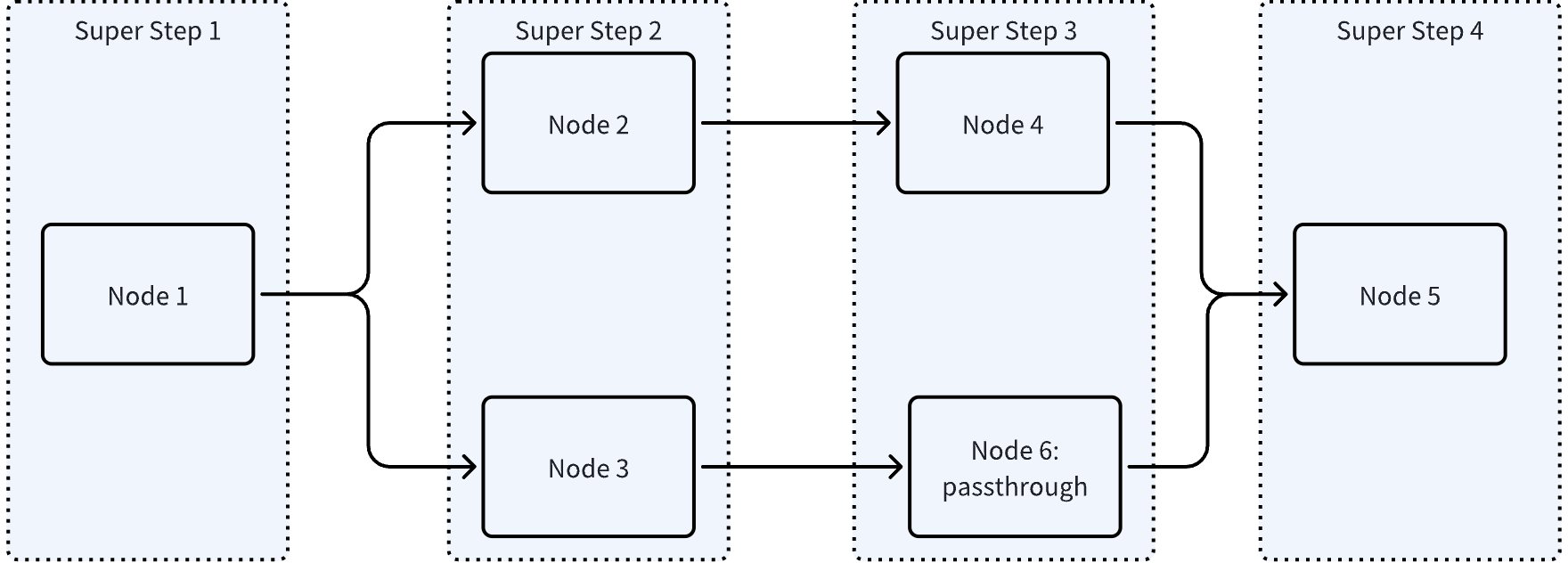
NodeTriggerMode == AllPredecessor 时,图以 dag 引擎执行,对应的拓扑结构是有向无环图。特点是:
- 每个节点有确定的前序节点,当所有前序节点都完成后,本节点才具备运行条件。
- 不支持图中有环,因为会打破“每个节点有确定的前序节点”这一假定。
- 支持 Branch。在运行时,将 Branch 未选中的节点记为已跳过,不影响 AllPredecessor 的语义。
💡 设置 NodeTriggerMode = AllPredecessor 后,节点会在所有前驱就绪后执行,但并不是立即执行,而是依然遵循 SuperStep——在一批节点全部执行完成后再运行新的可运行节点。
如果在 Compile 时传入 compose.WithEagerExecution(),则就绪的节点会立刻运行。
在 Eino v0.4.0 版本及之后的版本中,设置 NodeTriggerMode = AllPredecessor 后会默认开启 EagerExecution。
总结起来,pregel 模式灵活强大但有额外的心智负担,dag 模式清晰简单但场景受限。在 Eino 框架中,Chain 是 pregel 模式,Workflow 是 dag 模式,Graph 则都支持,可由用户从 pregel 和 dag 中选择。